Ever stared at a wall of floating-point numbers and felt your brain melt? That's the vibe from a recent X post by Hari Krishnaswamy, former Solidity lead and current CEO at Cantina, riffing on the nightmare of debugging matrix algorithms. His thread quotes Anthropic's announcement about fixing three overlapping bugs in Claude, and drops this gem of an image straight from their detailed postmortem report. It's a deep dive into one particularly tricky issue: a TPU implementation bug that made Claude's AI occasionally ghost its own best token picks.
Hari's take hits home for anyone who's wrestled with numerical gremlins in code. "Debugging matrix algorithms is nasty," he writes. "You stare at a bunch of floating point numbers and bang your head against a wall." Spot on. He shares how he once built an extended precision solver for a matrix routine, only for it to become a lifesaver in hunting down floating-point errors—those sneaky accumulations of tiny inaccuracies that snowball into big fails. It's a reminder that in high-stakes computing like AI token generation, one misplaced decimal can derail everything.
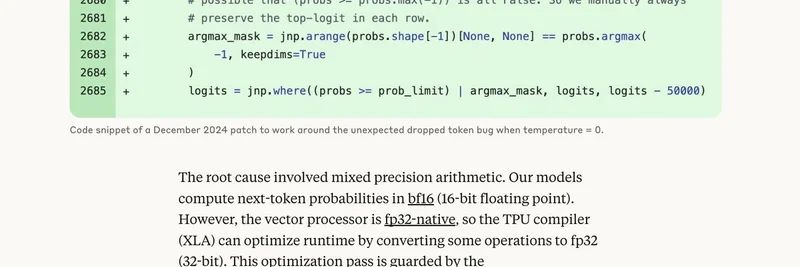
But let's zoom in on the bug itself, because it's a masterclass in why AI engineering is equal parts wizardry and witchcraft. Back in December 2024, Anthropic's team spotted their Tensor Processing Unit (TPU) setup—Google's beastly hardware for crunching AI math—occasionally dropping the most probable token when the temperature (a knob that controls output randomness) was set to zero. They slapped on a quick workaround to keep things humming.
That image? It's the smoking gun. The code hack manually preserves the top logit (the raw score before turning into probabilities) in each row to dodge edge cases where probability comparisons go haywire. But fast-forward to August 2025, and a code tweak accidentally unmasked a deeper gremlin in the XLA compiler—the tool that optimizes code for TPUs.
Here's the root cause, explained simply: Claude computes next-token probabilities in bf16 (a speedy 16-bit floating-point format to save memory and juice performance). TPUs, though, are native to fp32 (32-bit for more precision). The compiler, spotting an opportunity, auto-upgrades some ops to fp32 via a flag called xla_allow_excess_precision (defaults to true). Sounds smart, right? Wrong. This created a mismatch: parts of the "find the top-k tokens" math ran at different precisions, so they didn't agree on which token was boss. Boom—the highest-probability pick vanishes from contention.
It hit Claude Haiku 3.5 hard starting August 25, with ripples to Sonnet 4 and Opus 3. Users saw garbled outputs, like weird characters creeping into English text or syntax slips in code. Anthropic rolled back the change on September 4 for Haiku, September 12 for Opus, and proactively for Sonnet. Now, they're collaborating with XLA folks on a proper compiler fix, while running an exact top-k with bumped-up precision as a stopgap (minor speed hit, but hey, accuracy first).
This isn't just an AI oopsie—it's a cautionary tale for blockchain devs too. Think about it: meme token smart contracts or DeFi algos often lean on probabilistic models or matrix ops for pricing, yield farming, or even generative NFT art. A floating-point flub could mean lost funds or funky token drops. Hari's extended precision trick? Gold for auditing those edge cases in Solidity or Rust.
Anthropic's transparency here is chef's kiss. They owned the overlapping bugs (including a routing snafu and output corruption), shared reproducers with the XLA team, and beefed up their tests. For us in the crypto trenches, it's a nudge to double-down on precision checks and diverse hardware sims. Next time your model's acting sus, crank up that precision and see what shakes loose.
What do you think—ever debugged a floating-point phantom in your dApp? Drop your war stories below.