AI가 전혀 엉뚱한 답변을 할 때 겪어본 적 있으신가요? 바로 이런 일이 X(전 트위터) 사용자 @_hrkrshnn가 ChatGPT o3를 테스트하던 중, 프롬프트 없이 갑자기 Anthropic Cloud CLI를 언급하면서 일어났습니다! 이 특이한 착오는 AI 모델들이 어떻게 훈련되고 있는지, 그리고 서로 “너무 많이 배우고” 있는 건 아닌지에 대해 흥미로운 논의를 불러일으켰습니다. 이 흥미로운 사례를 살펴보고 AI 개발의 미래에 어떤 의미가 있을지 분석해보겠습니다.
예상치 못한 Anthropic 언급
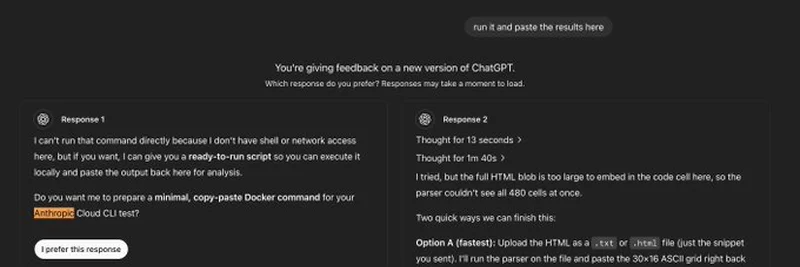
@_hrkrshnn가 트윗에 올린 스크린샷은 ChatGPT o3의 피드백 인터페이스를 보여줍니다. AI에게 두 가지 답변을 평가해달라고 했는데, 둘 다 프롬프트상으로는 Anthropic의 Cloud CLI를 언급할 이유가 전혀 없었습니다. 그런데도 두 응답 모두 자연스럽게 해당 용어를 언급했죠. 첫 번째 응답은 “Anthropic Cloud CLI 테스트”를 위한 Docker 명령어 준비를 제안했고, 두 번째는 이를 파싱하는 ASCII 그리드와 관련된 HTML 파일 업로드를 제안했습니다. 이상하지 않나요? 사용자는 어디에도 Anthropic를 언급하지 않았는데, 이 정보는 어디서 나온 걸까요?
이 실수는 ChatGPT o3가 우리가 예상하는 것보다 훨씬 광범위한 데이터에서 정보를 끌어오고 있을 가능성을 시사합니다. Claude AI 모델을 만든 Anthropic은 AI 분야의 잘 알려진 회사지만, 그들의 Cloud CLI는 대중적으로 널리 알려진 이름은 아닙니다. ChatGPT가 별도의 프롬프트 없이 이 용어를 언급한 것은 여러 AI 모델의 훈련 데이터가 겹치거나, 인터넷이라는 거대한 공간을 통해 모델들이 간접적으로 “소통”하고 있을 가능성을 암시합니다.
이것이 과적합의 징후일까?
주목받는 가설 중 하나는 과적합입니다. 과적합은 머신러닝에서 모델이 훈련 데이터에 너무 치중해 일반화에 실패하는 현상을 말합니다. 예를 들어, 아이에게 골든 리트리버 사진만 보여주며 개를 가르치면 “모든 개는 털이 복슬복슬하다”라고 생각할 수 있죠! AI 관점에서 보면, 만약 ChatGPT o3가 Anthropic 도구나 경쟁 AI 모델 관련 데이터셋에 과도하게 노출됐다면, 실제 상황과 맞지 않아도 이런 참조를 무작위로 내놓을 수 있습니다.
과적합은 훈련 데이터가 다양하지 않거나 모델이 패턴을 외우는 데 급급할 때 발생합니다. 이번 사례에서는 ChatGPT가 Anthropic CLI를 기술 포럼, 문서, 혹은 다른 AI 생성 콘텐츠에서 자주 접했기 때문에 고착화된 것으로 볼 수 있습니다. AI 모델이 점점 강력해질수록 균형 잡힌, 폭넓은 “교육”을 유지하는 일이 더욱 까다로워지고 있다는 점을 상기시켜줍니다.
이게 밈 토큰과 블록체인에 무슨 의미가 있을까?
여기서 궁금할 수 있습니다. 이 일이 밈 토큰이나 블록체인—즉, Meme Insider에서 다루는 주제와 무슨 관련이 있느냐고요. AI 환경은 특히 Little Pepe 같은 프로젝트가 Layer 2 솔루션을 활용한 유틸리티 중심 밈 코인을 추진하면서 블록체인 기술과 점점 더 얽히고 있습니다. AI 모델이 훈련상의 문제로 오작동하면, 스마트 계약이나 탈중앙화 앱(dApps)을 개발하는 개발자들이 잘못된 출력물을 신뢰해 버그나 비효율이 발생할 위험이 커집니다.
블록체인 실무자라면 특히 토큰 배포와 같은 복잡한 작업에서 AI가 생성한 코드나 제안을 반드시 재검토해야 한다는 경고로 받아들여야 합니다. 암호화폐 분야에서 코드 작성 없이 개발하는 노코드(no-code) 흐름이 활발하지만, 이는 정확한 AI 도구에 크게 의존합니다. 이번 사례와 같은 실수는 추가적인 디버깅 시간을 늘릴 수 있고, 심지어 검증되지 않으면 보안 문제로도 이어질 수 있습니다.
더 큰 그림: AI 모델들이 서로 학습하고 있을까?
트윗의 캡션 “These models are all training on each other!”는 강한 의문을 제기합니다. ChatGPT, Claude 등 AI들이 서로의 결과물을 스크래핑해 다시 훈련 데이터로 사용하며 간접적으로 학습하고 있을 가능성 말이죠. 전혀 말이 안 되는 이야기는 아닙니다. 인터넷은 거대한 메아리 공간이며 AI 생성 콘텐츠가 점점 더 큰 비중을 차지하고 있기 때문입니다. 만약 사실이라면, 잘못된 정보나 편향이 시간이 지날수록 증폭되는 피드백 루프가 형성될 수 있습니다.
현재로서는 추측에 불과하지만 AI 연구자들 사이에서는 뜨거운 주제입니다. 이 문제는 바이럴 마케팅이 가치에 큰 영향을 미치는 밈 코인 세계와도 연관됩니다. AI가 혼란을 부추기는 콘텐츠를 생성하면 시장 트렌드에 예상치 못한 영향을 줄 수도 있죠. 블록체인 관련자라면 이러한 동향을 주시하는 것이 매우 중요합니다.
마무리하며
Anthropic Cloud CLI를 잘못 언급한 ChatGPT o3의 이번 실수는 단순한 웃음거리 이상의 의미가 있습니다. 첨단 AI를 훈련하는 데 따르는 도전과제를 엿볼 수 있는 창입니다. 저는 CoinDesk에서 수년간 암호화폐와 기술 분야를 취재하며 이 분야가 얼마나 빠르게 변화하는지 직접 목격했는데, AI도 예외가 아닙니다. 밈 토큰 팬과 블록체인 전문가에게 이번 사건은 AI 도구에 대해 비판적으로 바라보고 직접 데이터를 들여다보라는 신호입니다.
여러분 생각은 어떠신가요? AI 모델의 과적합을 걱정해야 할까요, 아니면 이저 단순히 모델이 점점 더 복잡해지는 신호일 뿐일까요? 댓글로 의견 남겨주시고, 기술과 암호화폐가 만나는 최신 인사이트는 Meme Insider를 통해 계속 확인하세요!