有没有盯着一堆浮点数看得头脑发热过?这正是最近 Hari Krishnaswamy 在 X 上的帖子 那种感觉——他曾任 Solidity 负责人、现在是 Cantina 的 CEO,吐槽调试矩阵算法时的噩梦。他在推文里引用了 Anthropic 的公告,说明他们修复了 Claude 中三个互相重叠的 bug,并放出了一张来自他们详细事后分析报告 的图片。这是一次深入剖析里尤其棘手的一个问题:TPU 实现的 bug 会让 Claude 的 AI 偶尔把自己最可能选的 token 给“幽灵化”掉。
对于任何和数值“鬼怪”斗争过的人,Hari 的观点都很切中要害。“调试矩阵算法真是恶心,”他写道。“你盯着一堆浮点数,然后撞墙。”太对了。他分享了自己曾为某个矩阵例程写了一个扩展精度求解器,结果在追踪浮点误差时成了救命稻草——那些微小不准的累积会演变成巨大的失败。这提醒我们,在像 AI 生成 token 这种高风险计算里,一个小小的小数点错位就能把一切搞垮。
但我们把焦点放到这个 bug 本身,因为它堪称一堂 AI 工程既是巫术又是魔法的课程。回到 2024 年 12 月,Anthropic 团队发现他们的 Tensor Processing Unit (TPU) 配置——Google 用来处理 AI 计算的巨兽硬件——在温度(控制输出随机性的一个旋钮)设为 0 时,偶尔会把最可能的 token 给“丢掉”。他们先打了个临时补丁让系统勉强运行。
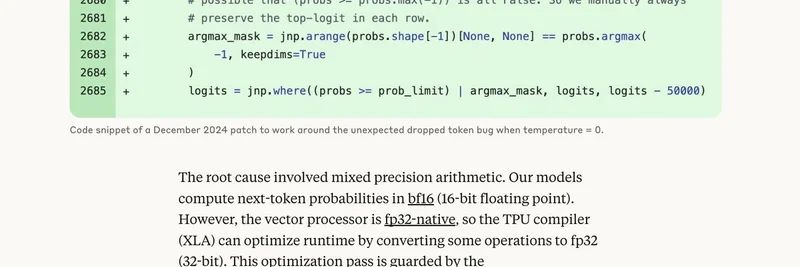
那张图?就是确凿证据。代码的临时修补手动在每一行中保留了 top logit(变成概率前的原始分数),以规避概率比较出错的边界情况。但快进到 2025 年 8 月,一次代码改动意外暴露了 XLA 编译器里更深层的幽灵——这玩意儿负责把代码为 TPU 优化。
根本原因,简单说就是:Claude 在 bf16(节省内存和提升性能的 16 位浮点格式)上计算下一个 token 的概率。TPU 原生偏向 fp32(32 位,精度更高)。编译器看到机会,通过一个名为 xla_allow_excess_precision 的开关(默认 true)自动把一些运算升级到 fp32。听起来聪明吧?其实不然。这造成了不匹配:负责“找 top-k token”那部分数学在不同精度下运行,结果它们在哪个 token 最可能这个问题上达不成一致。砰——最高概率的选择就从候选中消失了。
从 8 月 25 日起,这个问题严重影响了 Claude Haiku 3.5,并波及到 Sonnet 4 与 Opus 3。用户看到乱码输出,比如英文文本里冒出奇怪字符,或者代码的语法出错。Anthropic 在 9 月 4 日对 Haiku 回滚了该改动,Opus 在 9 月 12 日回滚,并且对 Sonnet 做了前瞻性的修复。现在他们正在和 XLA 团队合作做一个真正的编译器层面修补,同时以提升精度运行一次精确的 top-k 作为权宜之计(会有小幅性能损失,但准确性优先)。
这不只是一个 AI 的乌龙——对区块链开发者来说也是戒备的故事。想想看:meme token 的智能合约或 DeFi 算法常常依赖概率模型或矩阵运算来做定价、产率策略,甚至生成 NFT 艺术。一次浮点的失误可能意味着资金损失或异常的 token 掉落。Hari 那个扩展精度的技巧?对审计 Solidity 或 Rust 中的那些边缘情况简直是金子。
Anthropic 在这一点上的透明度堪称典范。他们承认了这些重叠的 bug(包括路由失误和输出损坏),与 XLA 团队共享了可复现的样例,并加强了测试覆盖。对于我们这些在 crypto 一线的人来说,这就是要提醒大家加倍重视精度检查和多样化的硬件模拟。下一次你的模型表现奇怪,调高精度看看会冒出什么问题。
你怎么看——在你的 dApp 里调试过浮点“幽灵”吗?把你的战争故事丢在下面分享吧。