有没有遇到过 AI 给出的回答完全不对劲?这正是 X 平台用户 @_hrkrshnn 测试 ChatGPT o3 时遇到的情况——AI 居然提到了 Anthropic Cloud CLI,而用户根本没有提及!这个奇怪的错乱引发了一场关于 AI 模型训练机制以及它们是否“相互学习”过头的有趣讨论。让我们深入剖析这一案例,探讨它对 AI 未来发展的可能影响。
意外的 Anthropic 引用
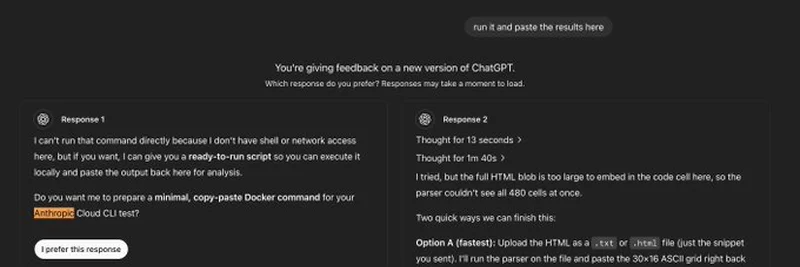
在这条推文中,@_hrkrshnn 分享了 ChatGPT o3 反馈界面的截图。AI 被要求评估两个回答,按理说都不该出现 Anthropic 的 Cloud CLI 相关内容。然而,两条回答却都随意提到了这个词,回答一甚至准备了一个用于“Anthropic Cloud CLI 测试”的 Docker 命令,回答二建议上传 HTML 文件以解析与之相关的 ASCII 网格。很怪异,对吧?用户根本没提到 Anthropic,这到底是怎么回事?
这次失误暗示 ChatGPT o3 可能在使用比我们想象中更广泛的数据集。Anthropic 是 Claude AI 模型背后的公司,是 AI 领域的重要参与者,但其 Cloud CLI 并不算家喻户晓。ChatGPT 无缘无故提到它,暗示不同 AI 模型的训练数据或许存在交叉,甚至可能是这些模型通过庞大的互联网“间接交流”。
这可能是过拟合在作祟?
一种流传的理论是过拟合——机器学习中常见的问题,模型过分“依赖”训练数据,难以泛化。打个比方,如果只用金毛猎犬的照片教孩子什么是狗,他们可能会以为所有狗都有蓬松的尾巴!在 AI 领域,如果 ChatGPT o3 的训练数据中大量包含了 Anthropic 工具或关于竞争 AI 模型的讨论,它就可能在不合适的时候抛出相关引用。
过拟合通常是因为训练数据不够多样,或者模型记住了模式而不是学会适应。这里,AI 可能因为在技术论坛、文档或其他 AI 生成内容中频繁“见到”Anthropic CLI,便将其纳入了回答库。这提醒我们,随着 AI 模型变得越来越强大,保证它们“受教”内容的广度和平衡变得尤为困难。
这对 Meme Token 和区块链意味着什么?
你可能会好奇,这和我们在 Meme Insider 关注的 meme token 或区块链有什么关系?答案是,AI 与区块链技术的结合日益紧密,尤其像 Little Pepe 这样的项目,推动了基于 Layer 2 解决方案的实用型 meme 币。如果 AI 模型因训练问题而出现失误,开发智能合约或去中心化应用(dApp)的开发者可能会依赖有误的结果,导致代码漏洞或效率低下。
对于区块链从业者来说,这提醒大家务必仔细核对 AI 生成的代码或建议,特别是那些复杂的代币部署任务。加密领域的无代码趋势令人兴奋,但它依赖准确的 AI 工具。一旦出现类似失误,就意味着额外的调试工作,甚至未加检验的安全风险。
更大的背景:AI 模型是否在彼此“相互训练”?
推文配文“这些模型都在彼此训练!”引人深思。是否 ChatGPT、Claude 等 AI 模型实际上在间接学习彼此的输出,因为这些内容被收录进新的训练数据?这并非无稽之谈。互联网就是一个巨大的回声室,AI 生成内容的比例也日益增大。若属实,这可能导致错误或偏见随着时间被放大,形成反馈循环。
目前这仍是猜测,但在 AI 研究领域备受关注。这也与 meme 币世界息息相关,那里病毒式炒作往往决定价值走向。如果 AI 开始生成助推这类炒作(或混乱)的内容,可能会以意想不到的方式影响市场走势。关注这些发展对区块链人士来说至关重要。
结语
ChatGPT o3 提及 Anthropic Cloud CLI 的这次小失误,不仅仅是一个好笑的bug,更是对训练最前沿 AI 模型面临挑战的一个窗口。作为曾在 CoinDesk 覆盖加密与科技多年的观察者,我见证了这一领域的快速演进,AI 也不例外。对于 meme token 爱好者和区块链专业人士来说,这是一记提醒——要保持对 AI 工具的怀疑态度,亲自核实数据和内容。
你怎么看?我们应不应该担心 AI 模型过拟合,还是这仅仅是它们日益复杂的表现?欢迎在评论区分享你的看法,别忘了关注 Meme Insider ,获取更多科技与加密交汇的深度洞察!