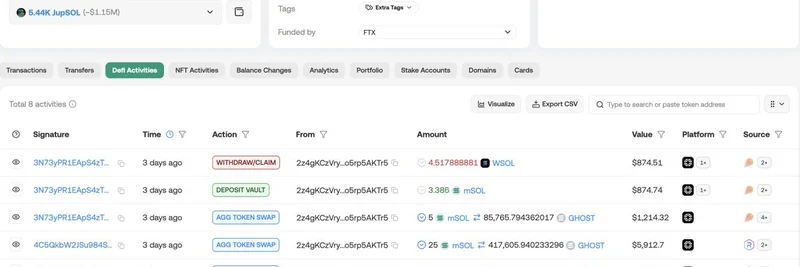
有没有想过最新的 AI 模型是否真的能像专业数学家那样处理复杂运算?作为一个多年深耕区块链代码的人——想想那些用 Solidity 编写、驱动从 DeFi 到狂热 meme token 发布的一切智能合约——我一直好奇 AI 会如何为我们的领域赋能。Cantina(https://cantina.xyz)和 Spearbit(https://spearbit.com)CEO、拥有 Solidity 开发背景的 Hari Krishnan 近期在一则 X 帖子 中给出了一组简短但意味深长的对比,可能预示着加密技术的大变动。
Hari 的看法很直白:“GPT-5 Pro 在数学方面真的很强。”然后他把它与 Google 的 Gemini Deep Think 相比,指出后者“还不够”,没有达到类似 International Mathematical Olympiad (IMO) 金牌级别的模型 的宣传效果。对外行来说,IMO 就像数学界的超级碗——高中生在做那些连资深人士都头疼的问题。DeepMind 早期的 AI 在那里拿到了银牌,所以门槛极高。
这不仅仅是闲聊。Hari 引用了他先前的一条推文,里头他用五个数学题测试了 Gemini Deep Think。结论?全面失败,甚至包含一道直接来自模型训练数据的问题。“它尽力去寻找‘归纳模式’,但推理不够好,”他写道。唉。顺便说一句,归纳推理就是那种类似福尔摩斯式的推断:从数据中发现模式以预测结果——这对从优化 meme coin 的 tokenomics 到验证复杂区块链证明的所有事情都至关重要。
这对我们 meme token 圈有什么意义?想象一下 GPT-5 Pro 那样精通数学的 AI。它能把病毒式代币背后的棘手计算自动化,比如预测 pump-and-dump 动态或在没有人为错误的情况下模拟 yield farming 策略。这样的工具或许能让 meme 创作更民主化,让开发者把精力放在有趣的文化点子上,而不是为 gas fees 里的二次方程调试头疼。反过来,如果像 Gemini 这样的模型继续出错,我们就会被提醒在高风险的区块链部署中必须有人类监督——尤其是一处错误的计算就可能把一个社区拖下水。
作为一名 Solidity 资深人士,Hari 的见解格外有分量。他在 Spearbit 的工作就是审计智能合约,捕捉那些往往归结为……没错,数学失误的漏洞。如果 GPT-5 持续进化,它可能会成为 Meme Insider 上构建下一个 Dogecoin 接班人时的终极副驾驶。